MySQL面试题——索引的数据结构
本文共 1370 字,大约阅读时间需要 4 分钟。
数据库查询是数据库的最主要功能之一。最基本的查询算法就是顺序查找,这种复杂度为O(n)的算法在数据量很大时是性能很差的。
1.B树索引和B+树索引
目前大部分数据库系统和文件系统都采用B-Tree或者B+Tree作为索引结构。
B-Tree
为了描述B-Tree,首先定义一条数据记录为一个二元组[key,data],key为记录的键值,对于不同的数据记录,key是互不相同的。data为数据记录除key外的数据。
由于B-Tree树的特性,在B-Tree中按照key检索数据的算法就为:- 首先从根节点进行二分查找,如果找到则返回对应节点的data
- 否则就对相应区间的指针指向的节点递归查找,直到找到节点或者找到null
带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上做了优化,增加了顺序访问指针
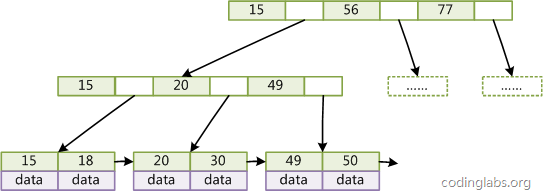 如上图所示:在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能
如上图所示:在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能 B-/+索引的性能分析
索引以索引文件的形式存储在磁盘中(因为索引文件也有可能很大,所以将索引文件存放在内存中不现实,也没有必要),这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数
我们需要知道的是,从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读,如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多的数据,那我们查找数据的时间也会大幅度降低
所以在B-Tree的设计中,运用了计算机的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入了在B树的结构中:

B+树
B+树是对B树的进一步优化。

- B+树非叶子节点是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据(如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树,在B+树中,阶数就等于键值个数)就更大,那么整颗数就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数又会再次减少,数据查询的效率也会更快)
1.3 B+Tree性质
- n颗子树的节点包含n个关键字,不用来保存数据而是用来保存数据的索引
- 所有的叶子节点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接
- 所有非终端节点可以看成是索引部分,节点中仅含有其子树中的最大(最小)关键字
- B+树中,数据对象的插入和删除仅在叶节点上进行
- B+树有两个头指针,一个是树的根节点,一个是最小关键码的叶节点
转载地址:http://lqjmb.baihongyu.com/
你可能感兴趣的文章
C++ 程序员到高级架构师,必须经历的三个阶段
查看>>
和 Java、C# 等语言对比后,Python 简直酷上天了!
查看>>
程序媛到最后,拼的到底是什么?
查看>>
笑死!996 程序员竟然做了这个梦!| 每日趣闻
查看>>
“再见,微软!”
查看>>
ARM 发布新一代 CPU 和 GPU,实现 20% 性能提升!
查看>>
技术引路:机器学习仍大有可为,但方向在哪里?
查看>>
漫画:如何给女朋友解释什么是编译与反编译
查看>>
刷屏了!这篇 Python 学习贴,90% 的程序员都用的上!
查看>>
漫画:如何给女朋友解释什么是适配器模式?
查看>>
程序员又迎来一个好消息! | 每日趣闻
查看>>
Mac 被曝存在恶意漏洞:黑客可随意调动摄像头,波及四百万用户!
查看>>
拒绝与其他码农一致!CSDN定制T让你成为最靓的仔
查看>>
程序员情商低?看完这 4 类程序员我懂了!
查看>>
《长安十二时辰》里你不能不知道的 IT 技术 | 每日趣闻
查看>>
程序员爬取 3 万条评论,《长安十二时辰》槽点大揭秘!
查看>>
一年参加一次就够,全新升级的 AI 开发者大会议程出炉!
查看>>
基于 XDanmuku 的 Android 性能优化实战
查看>>
基于嵌入式操作系统的物联网安全
查看>>
一个只有 99 行代码的 JS 流程框架
查看>>